 일반적인 확률 변수Normal Random Variable
일반적인 확률 변수Normal Random Variable
📅
누적 분포 함수: CDF (Culmulative Distribution Function, CDF) 🔗
대신 가 필요할 때 사용
예시
- 버스가 1시 30분 전에 도착할 확률은 얼마인가?
- 무작위로 선택된 사람이 키가 5피트 7인치 이하일 확률은 얼마인가?
- 이번 달 강수량이 3인치 미만일 확률은 얼마인가?
확률 변수 의 CDF는 로 표기되며 의 확률을 제공한다.
이산 확률 변수의 CDF (Discrete Random Variable: CDF) 🔗
가 이산형일 때, 는 의 구간마다 일정한 값을 가지는 함수
연속 확률 변수의 CDF (Continuous Random Variable: CDF) 🔗
가 연속형일 때, 는 의 연속 함수
CDF는 단조 증가(monotonically increasing)하다
는 일 때 0, 일 때 1에 수렴한다.
예제 (구간별 상수 확률 밀도 함수) 🔗
문제 🔗
알빈의 출근 시간은 15분에서 20분 사이일 확률이 2/3이고, 20분에서 25분 사이일 확률이 1/3이다. 각각의 시간은 동일한 확률로 발생한다. PDF를 작성할 수 있는가?
CDF는 어떻게 되는가?
해결 🔗
PDF
CDF
- PDF를 적분하여 구할 수 있다.
정규 확률 변수 (Normal Random Variable) 🔗
연속 확률 변수 가 다음 형태의 PDF를 가지면 정규 분포 또는 가우시안 분포를 따른다고 한다.
평균: E[X] =
분산: var(X) =
정규 확률 변수의 특징 1. 대칭성 (Symmetry of Normal Random Variable) 🔗
정규 확률 변수는 평균 를 중심으로 대칭이다.
정규 확률 변수의 특징 2. 선형 변환 (Linear Transformation of Normal Random Variable) 🔗
가 정규 분포를 따르면, 도 정규 분포를 따른다.
평균: E[Y] =
분산: var(Y) =
정규 확률 변수의 특징 3. 표준 정규 확률 변수 (Standard Normal Random Variable) 🔗
평균이 0이고 분산이 1인 정규 확률 변수를 표준 정규 확률 변수라고 한다.
표준화
가 평균 와 분산 를 가진 정규 확률 변수라고 하자. 우리는 를 다음과 같이 표준 정규 확률 변수 로 표준화한다.
증명 (표준 정규 확률 변수) 🔗
정규 확률 변수 가 주어졌을 때,
표준화를 통해,
- 는 평균 및 분산 을 가지는 표준 정규 확률 변수가 된다.
증명: 가 의 선형 변환이기 때문에, 는 정규 분포를 따른다. 더불어,
따라서, 는 표준 정규 확률 변수다.
표준 정규 확률 변수의 CDF (CDF of Standard Normal Random Variable) 🔗
표준 정규 확률 변수 의 CDF는 로 표기한다.
가 표준 정규 확률 변수일 때, 의 CDF는 다음과 같다.
- 이를 분석적으로 계산할 수 없다.
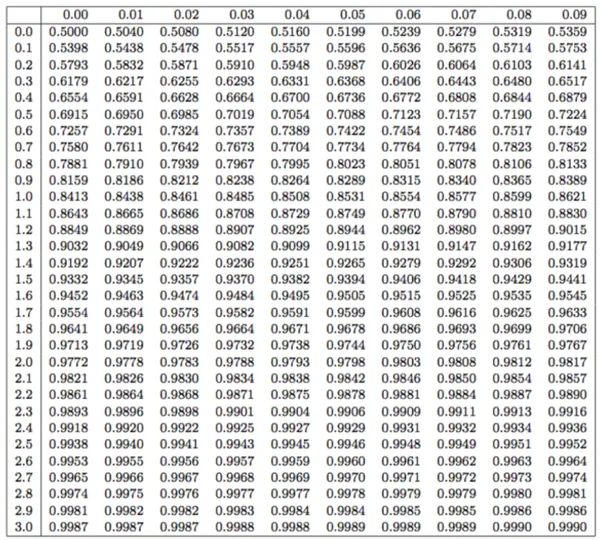
- 대신, 표준 정규 분포표를 사용하여 일 때 값을 확인한다.
예시 (표준 정규 분포표) 🔗
| .00 | .01 | .02 | .03 | .04 | ... | |
|---|---|---|---|---|---|---|
| 0.0 | 0.5000 | 0.5040 | 0.5080 | 0.5120 | 0.5160 | ... |
| 0.1 | 0.5398 | 0.5438 | 0.5478 | 0.5517 | 0.5557 | ... |
| 0.2 | 0.5793 | 0.5832 | 0.5871 | 0.5910 | 0.5948 | ... |
| 0.3 | 0.6179 | 0.6217 | 0.6255 | 0.6293 | 0.6331 | ... |
| ... | ... | ... | ... | ... | ... | ... |
예제 (표준 정규 확률 변수의 CDF) 🔗
문제 🔗
특정 지역의 연간 강설량은 평균 인치, 표준 편차 인 정규 확률 변수로 모델링된다. 올해의 강설량이 최소 80인치일 확률은 얼마인가?
해결 🔗
- 를 연간 강설량으로 정의한다.
- 를 계산해야 한다. 이는 CDF다.
- CDF는 표준 정규 분포표를 사용하여 효율적으로 계산할 수 있다.
- 주의: 표준 정규 분포표는 가 표준 정규 확률 변수일 때만 사용할 수 있다.
- 는 표준 정규 확률 변수가 아니므로 표준화가 필요하다.
표준화를 통해, 표준 정규 확률 변수 를 구한다.
그러면
요약 (Summary) 🔗
정규 확률 변수
(Normal Random Variable)
연속 확률 변수 가 다음 형태의 PDF를 가지면 정규 분포 또는 가우시안 분포를 따른다고 한다.여기서 와 는 각각 평균과 분산으로, PDF를 특징짓는다.
표준화
(Standardization)
가 평균 와 분산 를 가지는 정규 확률 변수라고 하자. 우리는 를 표준 정규 확률 변수 로 표준화할 수 있다.추가 문제 🔗
문제 🔗
가 평균이 0이고 표준 편차가 인 정규 확률 변수라고 하자.
표준 정규 분포표를 사용하여 다음 사건의 확률을 계산하라:
및 for
해결 🔗
를 표준 정규 확률 변수로 정의하자.
표에 의하면,