 MongoDB 아키텍처 이해 - MongoDB 올인 2일차Understanding MongoDB Architecture - All-in Day 2
MongoDB 아키텍처 이해 - MongoDB 올인 2일차Understanding MongoDB Architecture - All-in Day 2
📅
들어가기 전에 🔗
지난 시간에는 MongoDB가 무엇인지, 왜 많은 개발자들이 사용하게 되었는지에 대한 배경 이야기를 나누었습니다.
오늘은 MongoDB가
내부적으로 어떻게 동작하는지
, 그 구조(아키텍처)에 대해 조금 더 깊이 알아보겠습니다.데이터는 어떻게 저장될까요? 문서 지향 스토리지 🔗
지난 시간에 MongoDB는 '문서(Document)' 단위로 데이터를 저장한다고 말씀드렸던 것 기억나시나요?
이것이 MongoDB 아키텍처의 가장 기본적인 특징입니다.
마치 우리가 정보를 워드 문서나 메모장에 기록하듯, MongoDB는 관련 정보를 하나의
문서
안에 담아 저장합니다.기존의 관계형 데이터베이스(RDB)는 데이터를 표(Table) 형태로 저장합니다.
각 정보는 정해진 칸(Column)에 맞추어 한 줄(Row)씩 입력됩니다. 모든 줄은 같은 구조를 가져야 하죠.
이미지 제안: 왼쪽에는 엑셀 시트처럼 격자로 나누어진 표(RDB), 오른쪽에는 자유로운 형식의 여러 문서 뭉치(MongoDB)를 비교하는 그림
하지만 MongoDB의 문서는 JSON과 비슷한 BSON(Binary JSON) 형식을 사용합니다.
하나의 문서 안에는 다양한 형태의 정보(이름, 나이, 취미 목록, 주소 등)가 계층적으로 들어갈 수 있습니다.
{
"_id": "ObjectId('...some unique id...')", // 문서 고유 식별자
"이름": "홍길동",
"나이": 30,
"연락처": {
"이메일": "gildong@example.com",
"휴대폰": "010-1234-5678"
},
"수강과목": ["데이터베이스", "알고리즘"],
"등록일": new Date() // 날짜 정보도 저장 가능
}위 예시처럼 '연락처' 정보 안에 '이메일'과 '휴대폰'이라는 하위 정보가 들어갈 수도 있고, '수강과목'처럼 여러 개의 값을 배열로 가질 수도 있습니다.
이렇게
데이터를 표현하는 방식이 유연
하다는 것이 문서 지향 스토리지의 큰 장점입니다.
RDB와 MongoDB의 차이
데이터 정리함: 컬렉션과 문서 🔗
그렇다면 이 문서들은 어디에 보관될까요?
MongoDB는 다음과 같은 계층 구조로 데이터를 정리합니다.
- 데이터베이스(Database): 가장 큰 저장 단위입니다. 여러 개의 컬렉션을 가질 수 있습니다.
- 컬렉션(Collection): 문서(Document)들을 모아 놓는 곳입니다. 관계형 데이터베이스의 '테이블'과 비슷한 개념이지만, 컬렉션 안의 문서들은구조가 서로 달라도 됩니다.
- 문서(Document): 실제 데이터가 저장되는 기본 단위입니다. BSON 형식으로 되어 있습니다.
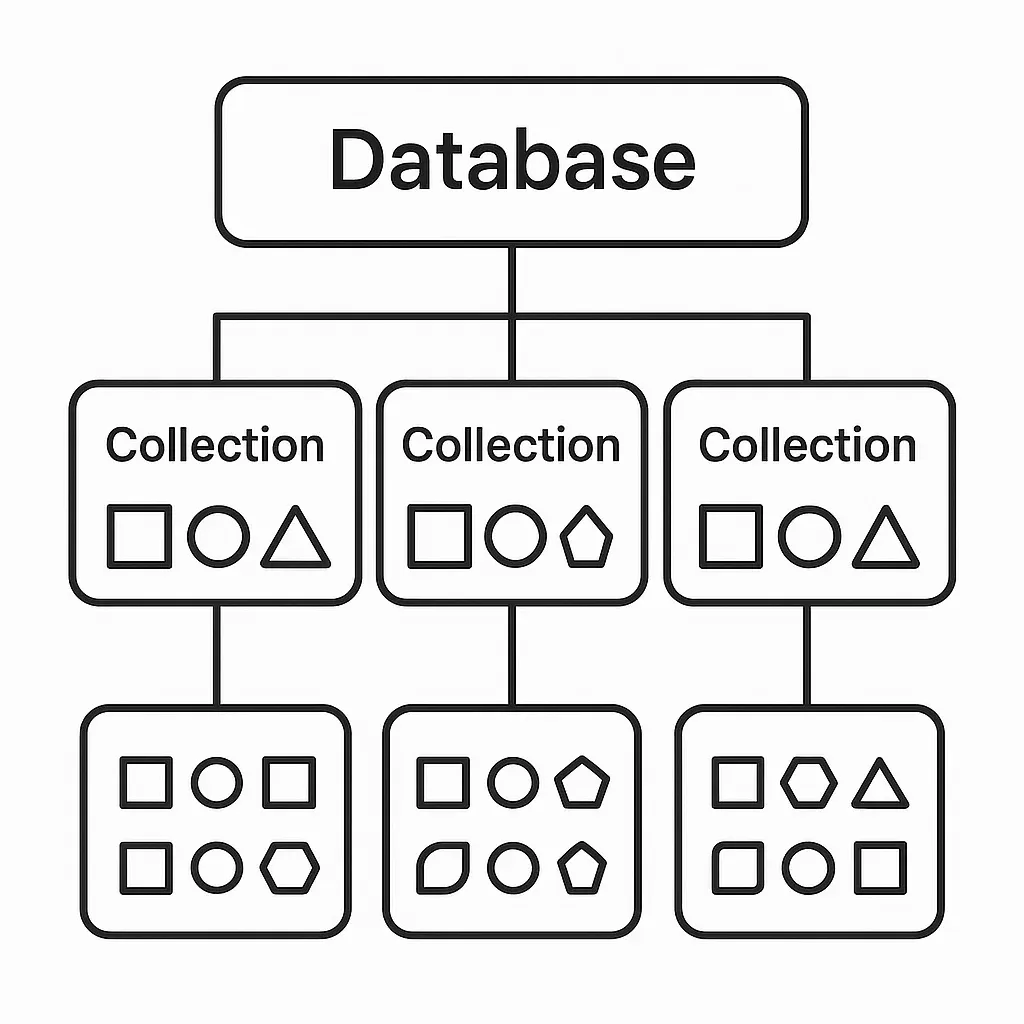
MongoDB 계층도
복제 세트 (Replica Set) 🔗
우리가 만든 서비스가 항상 안정적으로 동작하려면, 데이터베이스 서버에 문제가 생겨도 서비스가 중단되지 않아야 합니다.
이것을
고가용성(High Availability)
이라고 부릅니다.
MongoDB는 복제 세트 기능을 통해 고가용성을 지원합니다.복제 세트는
똑같은 데이터를 가진 MongoDB 서버 여러 대를 묶어서
운영하는 방식입니다.
복제 세트는 보통 다음과 같이 구성됩니다.- 프라이머리(Primary)노드: 데이터 읽기 및 쓰기 작업을 담당하는 '대장' 서버입니다. 오직 한 대만 존재합니다.
- 세컨더리(Secondary)노드: 프라이머리 노드의 데이터를 그대로 복제하여 가지고 있는 '부하' 서버들입니다. 여러 대가 있을 수 있습니다. 데이터 읽기 작업은 분담할 수 있지만, 쓰기 작업은 할 수 없습니다.

Primary/Secondary 노드드
만약 프라이머리 서버에 갑자기 문제가 생기면 어떻게 될까요?
복제 세트는 자동으로 세컨더리 서버 중 하나를 새로운 프라이머리로 선출합니다(이 과정을
Failover
라고 합니다).
이 덕분에 잠시의 중단은 있을 수 있지만, 서비스 전체가 멈추는 것을 막을 수 있습니다. 데이터를 안전하게 보관하고 서비스 연속성을 확보하는 중요한 기능입니다.샤딩 (Sharding) 🔗
서비스가 엄청나게 커져서 데이터 양이 수 테라바이트(TB) 이상으로 많아지면, 서버 한 대(또는 복제 세트 하나)만으로는 감당하기 어려워질 수 있습니다.
이럴 때 필요한 기술이 바로
샤딩
입니다.샤딩은
아주 큰 데이터셋을 여러 개의 작은 조각으로 나누어
여러 서버(또는 복제 세트)에 분산하여 저장하고 처리하는 기술입니다.
마치 거대한 책 한 권을 여러 챕터로 나누어 여러 사람이 동시에 읽고 작업하는 것과 비슷합니다.
이를 통해 MongoDB는 수평 확장(Scale-out)
을 할 수 있게 됩니다.샤딩 환경(샤드 클러스터)은 보통 다음과 같은 요소들로 구성됩니다.
- 샤드(Shard): 실제 데이터 조각을 저장하는 서버 또는 복제 세트입니다. 여러 개의 샤드가 존재합니다.
- 몽고스(mongos): 클라이언트의 요청을 받아서 어떤 데이터가 어느 샤드에 있는지 판단하고 해당 샤드로 요청을 전달하는라우터역할을 합니다. 클라이언트는 샤드의 존재를 직접 알 필요 없이 몽고스에만 접속하면 됩니다.
- 컨피그 서버(Config Servers): 클러스터의 설정 정보, 즉 어떤 데이터가 어느 샤드에 분산되어 있는지 등의메타데이터를 저장하고 관리하는 서버입니다. 이 정보가 매우 중요하므로 보통 복제 세트로 구성됩니다.
샤딩을 사용하면 다음과 같은 장점이 있습니다.
- 대용량 데이터 저장: 저장 공간의 한계를 극복할 수 있습니다.
- 성능 향상: 읽기 및 쓰기 작업을 여러 샤드에서 병렬로 처리하여 성능을 높일 수 있습니다.
물론 샤딩은 구조가 복잡해지고 관리 포인트가 늘어난다는 단점도 있어서, 정말 대규모 데이터가 필요한 경우가 아니라면 복제 세트만으로도 충분할 수 있습니다.
결론 🔗
오늘은 MongoDB의 핵심 아키텍처에 대해 알아보았습니다.
데이터를 유연한
문서
형태로 저장하고, 이 문서들을 컬렉션
에 담아 관리한다는 점을 배웠습니다.
또한, 서비스 안정성을 높이기 위한 *복제 세트(Replica Set)*와 대규모 데이터를 효율적으로 처리하기 위한 *샤딩(Sharding)*이라는 중요한 개념도 살펴보았습니다.이러한 MongoDB의 내부 구조를 이해하는 것은 앞으로 MongoDB를 설치하고, 데이터를 모델링하고, 쿼리를 작성하는 모든 과정에 든든한 기초가 될 것입니다.
다음 시간에는 MongoDB를 우리 컴퓨터에 직접 설치하고 기본적인 환경 설정을 하는 방법에 대해 알아보겠습니다.
참고 🔗
- MongoDB 아키텍처 가이드 (영문): https://www.mongodb.com/basics/mongodb-architecture↗
- MongoDB 복제 세트 문서 (영문): https://www.mongodb.com/docs/manual/replication/↗
- MongoDB 샤딩 문서 (영문): https://www.mongodb.com/docs/manual/sharding/↗