 PyMongo 기본기와 Atlas 연동 - Mongodb와 Python (상)PyMongo Basics and Atlas Connection - MongoDB and Python (Part 1)
PyMongo 기본기와 Atlas 연동 - Mongodb와 Python (상)PyMongo Basics and Atlas Connection - MongoDB and Python (Part 1)
📅
들어가기 전에 🔗
본편 시리즈에서 잠시 맛보았던 Python과 MongoDB를, 이번 외전 시리즈에서는 훨씬 더 깊이 있게 탐구해 볼 예정입니다.
총 3편에 걸쳐 Python 환경에서 MongoDB를 얼마나 다양하고 강력하게 활용할 수 있는지 함께 알아보겠습니다.
외전 (상)편인 오늘 이 시간에는 Python의 공식 MongoDB 드라이버인
PyMongo
의 기본적인 사용법을 다시 한번 탄탄히 다지고, MongoDB Atlas 클러스터와의 연결 설정을 좀 더 심도 있게 살펴보겠습니다.
또한, 단순히 데이터를 넣고 빼는 것을 넘어, 다양한 옵션을 활용한 CRUD 작업과 MongoDB의 핵심 데이터 형식인 BSON을 Python에서 어떻게 다루는지 자세한 예제와 함께 배워볼 것입니다.PyMongo 설치 및 개발 환경 설정 복습 🔗
Python에서 MongoDB를 사용하기 위한 첫걸음은
PyMongo 드라이버를 설치하는 것입니다. 본편에서 간략히 언급했지만, 여기서 다시 한번 상세히 짚고 넘어가겠습니다.1. Python 및 pip 설치 확인 🔗
Python이 이미 설치되어 있고, Python 패키지 관리자인
pip가 사용 가능한 상태여야 합니다. 터미널(Windows는 명령 프롬프트 또는 PowerShell)에서 다음 명령으로 확인할 수 있습니다.python3 --version
# 또는 python --version
pip3 --version
# 또는 pip --version만약 설치되어 있지 않다면, Python 공식 웹사이트(https://www.python.org/↗)에서 다운로드하여 설치합니다. pip는 보통 Python 설치 시 함께 설치됩니다.
2. 가상 환경 사용 권장 (선택 사항이지만 강력 추천) 🔗
여러 Python 프로젝트를 진행하거나 프로젝트별 의존성을 깔끔하게 관리하고 싶다면, 가상 환경(Virtual Environment)을 사용하는 것이 매우 좋습니다.
# 가상 환경 생성 (예: my_mongo_project_env 이름으로)
python3 -m venv my_mongo_project_env
# 가상 환경 활성화
# macOS/Linux
source my_mongo_project_env/bin/activate
# Windows (명령 프롬프트)
my_mongo_project_env\Scripts\activate.bat
# Windows (PowerShell)
my_mongo_project_env\Scripts\Activate.ps1가상 환경이 활성화되면 프롬프트 앞에
(my_mongo_project_env)와 같이 가상 환경 이름이 표시됩니다.3. PyMongo 및 dnspython 설치 🔗
활성화된 가상 환경(또는 시스템 전역)에 PyMongo를 설치합니다. Atlas의
mongodb+srv:// 형태의 연결 문자열을 사용하려면 dnspython 패키지도 필요합니다.pip install "pymongo[srv]"[srv]를 붙여 설치하면 pymongo와 함께 dnspython이 자동으로 설치됩니다. 만약 따로 설치하고 싶다면 다음과 같이 실행합니다.pip install pymongo
pip install dnspython설치가 완료되면, Python 스크립트에서
import pymongo를 통해 PyMongo를 사용할 수 있게 됩니다.MongoDB Atlas 연결 🔗
전체 코드는 여기에서 확인할 수 있습니다.
본편에서도 Atlas 연결 문자열을 사용하는 기본 방법을 배웠습니다. 이제 PyMongo의
MongoClient를 사용하여 Atlas에 연결할 때 고려할 수 있는 몇 가지 추가 옵션과 연결 관리에 대해 더 자세히 알아보겠습니다.MongoClient와 연결 문자열 🔗
기본적인 연결은 다음과 같습니다.
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure # 연결 오류 처리를 위해
# Atlas 연결 문자열 (실제 값으로 대체)
uri = "mongodb+srv://<username>:<password>@<cluster-url>/<dbname>?retryWrites=true&w=majority"
client = None
try:
client = MongoClient(uri)
# 연결 성공 여부 확인 (ping 명령은 서버에 간단한 명령을 보내 응답을 확인)
client.admin.command('ping')
print("MongoDB Atlas에 성공적으로 연결되었습니다!")
except ConnectionFailure as e:
print(f"Atlas 연결 실패: {e}")
except Exception as e:
print(f"알 수 없는 오류 발생: {e}")
# finally:
# if client:
# client.close() # 실제 애플리케이션에서는 적절한 시점에 닫아야 함MongoClient(uri, ...): 생성자는 URI 외에도 다양한 연결 옵션을 직접 매개변수로 받을 수 있습니다.- serverSelectionTimeoutMS서버 선택 시간 초과 (기본값 30000ms). 이 시간 내에 연결 가능한 서버를 찾지 못하면 오류 발생.
- connectTimeoutMS소켓 연결 시간 초과 (기본값 없음, 시스템 설정 따름).
- socketTimeoutMS소켓 작업 시간 초과 (기본값 없음).
- tls(boolean) TLS/SSL 사용 여부.
mongodb+srv://URI는 기본적으로 TLS를 사용합니다. - tlsCAFile, tlsCertificateKeyFile사용자 정의 TLS 인증서 사용 시.
연결 풀링(Connection Pooling) 이해하기 🔗
MongoClient 인스턴스는 내부에
연결 풀(Connection Pool)
을 가지고 있습니다.
이는 MongoDB 서버와의 TCP 연결을 미리 여러 개 만들어두고 재사용함으로써, 매번 연결을 새로 맺고 끊는 비용을 줄여 성능을 향상시키는 중요한 기능입니다.- 하나의 MongoClient 인스턴스대부분의 애플리케이션에서는하나의하여 애플리케이션 전체에서 공유하며 사용하는 것이 권장됩니다. 각 요청마다
MongoClient인스턴스만 생성MongoClient를 새로 생성하면 연결 풀의 이점을 살릴 수 없고 성능 저하를 유발합니다. - 자동 재연결네트워크 문제 등으로 일시적으로 연결이 끊어졌을 때,
MongoClient는 자동으로 재연결을 시도합니다. (retryWrites 옵션과 연관) - maxPoolSize연결 풀의 최대 연결 수 (기본값 100).
- minPoolSize연결 풀의 최소 연결 수 (기본값 0).
- waitQueueTimeoutMS풀에서 사용 가능한 연결이 없을 때 요청이 대기하는 최대 시간.
# 예시: MongoClient 생성 시 연결 풀 옵션 지정
client = MongoClient(uri, maxPoolSize=50, serverSelectionTimeoutMS=5000)일반적으로 기본 연결 풀 설정을 변경할 필요는 없지만, 매우 높은 동시성을 처리해야 하는 특정 상황에서는 튜닝을 고려할 수 있습니다.
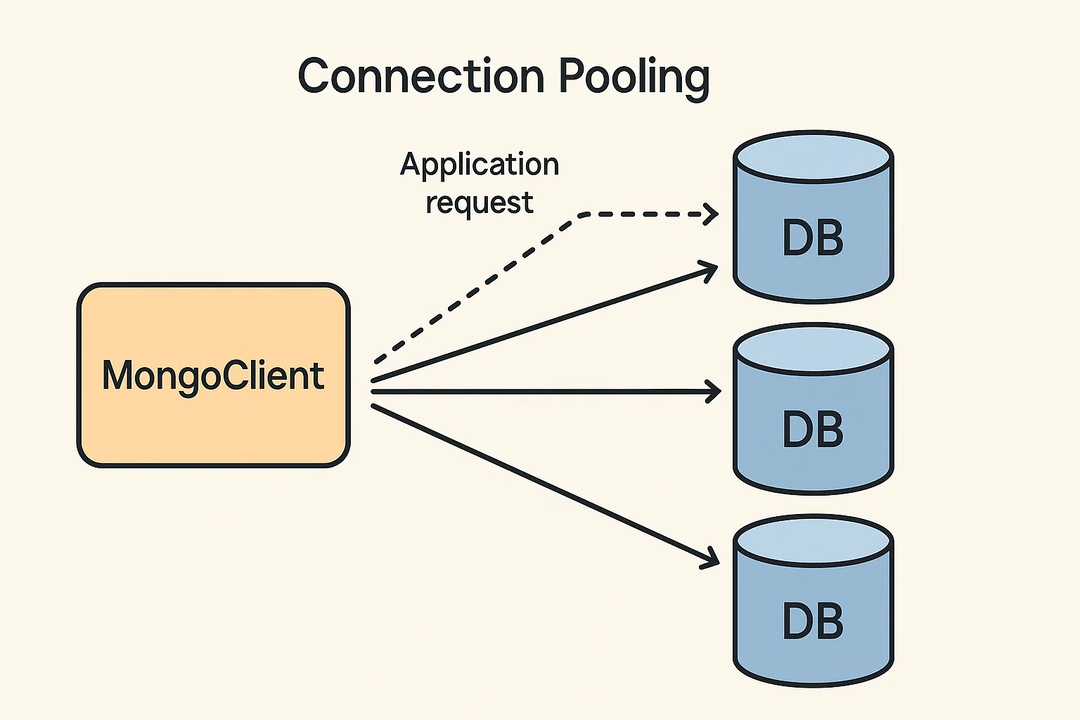
연결 풀 개념도
연결 종료 client.close() 🔗
애플리케이션이 종료되거나 더 이상 MongoDB 접속이 필요하지 않을 때는
client.close()를 호출하여 모든 연결 풀의 연결을 깨끗하게 닫아주는 것이 좋습니다.
웹 애플리케이션의 경우, 서버가 시작될 때 MongoClient를 생성하고 서버가 종료될 때 close()를 호출하는 패턴이 일반적입니다.PyMongo CRUD 작업 🔗
이제 Atlas에 안정적으로 연결되었으니, 기본적인 CRUD 작업을 더 자세히 살펴보겠습니다.
사용할 컬렉션 객체를 먼저 얻습니다.
# ... client 연결 성공 후 ...
db = client.myAppDB # 또는 client['myAppDB']
users_collection = db.users # 또는 db['users']1. 데이터 생성: Create 🔗
insert_one(document) 🔗
하나의 문서를 삽입합니다.
반환 값:
InsertOneResult 객체.inserted_id: 삽입된 문서의_id값 (ObjectId).acknowledged: (boolean) 쓰기 작업이 쓰기 고려(Write Concern) 설정에 따라 서버에 의해 확인되었는지 여부.
from bson.objectid import ObjectId # ObjectId 사용을 위해
import datetime
new_user_doc = {
"name": "유관순",
"age": 18,
"email": "yoo@example.com",
"tags": ["patriot", "activist"],
"joined_date": datetime.datetime.now(datetime.timezone.utc)
}
result_one = users_collection.insert_one(new_user_doc)
print(f"문서 하나 삽입 성공, ID: {result_one.inserted_id}, 확인됨: {result_one.acknowledged}")insert_many(documents, ordered=True) 🔗
여러 문서를 한 번에 삽입합니다.
documents는 문서들의 리스트입니다.
ordered=True (기본값): 문서들이 순서대로 삽입되며, 중간에 오류 발생 시 나머지 삽입 작업은 중단됩니다.
ordered=False: 순서에 관계없이 삽입을 시도하며, 오류가 발생해도 다른 문서들의 삽입은 계속 진행됩니다. (오류는 모아서 보고됨)
반환 값: InsertManyResult 객체.inserted_ids: 삽입된 모든 문서의_id값들의 리스트 (ObjectId 리스트).acknowledged: (boolean)
new_users_list = [
{"name": "안중근", "age": 30, "occupation": " 독립운동가"},
{"name": "윤봉길", "age": 24, "occupation": " 독립운동가", "_id": ObjectId()}, # 직접 _id 지정 가능
{"name": "김구", "age": 50, "email": "kimkoo@example.com"} # 일부러 다른 구조
]
try:
result_many = users_collection.insert_many(new_users_list, ordered=False)
print(f"여러 문서 삽입 성공, ID들: {result_many.inserted_ids}")
except pymongo.errors.BulkWriteError as bwe:
print(f"대량 쓰기 오류 발생: {bwe.details}") # ordered=False 시 개별 오류 확인 가능2. 데이터 조회: Read 🔗
find_one(filter=None, projection=None, sort=None, ...) 🔗
filter: 쿼리 조건 (딕셔너리).
projection: 반환할 필드 지정 (딕셔너리, 예: {"name": 1, "_id": 0}).
sort: 정렬 기준 (리스트 오브 튜플, 예: [("age", pymongo.DESCENDING)]).
조건에 맞는 첫 번째 문서를 반환하거나, 없으면 None을 반환합니다. # 나이가 가장 많은 사용자 한 명 찾기 (age 필드 내림차순 정렬 후 첫 번째)
oldest_user = users_collection.find_one(
sort=[("age", pymongo.DESCENDING)],
projection={"name": 1, "age": 1, "_id": 0}
)
if oldest_user:
print(f"나이가 가장 많은 사용자: {oldest_user}")find(filter=None, projection=None, skip=0, limit=0, sort=None, ...) 🔗
skip: 지정된 수만큼 문서를 건너뜁니다 (페이징).
limit: 반환할 최대 문서 수를 제한합니다.
조건에 맞는 문서들을 가리키는 Cursor 객체를 반환합니다.
커서는 이터러블(iterable)이므로 for 루프로 순회하거나 list()로 변환할 수 있습니다. # "독립운동가" 직업을 가진 사용자 중 처음 2명만, 이름과 나이만 조회
freedom_fighters = users_collection.find(
{"occupation": " 독립운동가"},
projection={"name": 1, "age": 1, "_id": 0},
limit=2,
sort=[("name", pymongo.ASCENDING)] # 이름 오름차순 정렬
)
print("독립운동가 명단 (처음 2명):")
for fighter in freedom_fighters: # 커서 순회
print(fighter)
# 커서의 count_documents() 메서드로 조건에 맞는 문서 수 확인 가능 (MongoDB 3.7+ 권장)
# count = users_collection.count_documents({"occupation": " 독립운동가"})
# print(f"총 독립운동가 수: {count}")3. 데이터 수정: Update 🔗
update_one(filter, update, upsert=False, ...) 🔗
filter 조건에 맞는 첫 번째 문서를 update 내용으로 수정합니다.
update: 업데이트 연산자 사용 (예: {"$set": {"age": 31}, "$inc": {"visits": 1}}).
upsert=True: 조건에 맞는 문서가 없으면 새로운 문서를 삽입합니다 (Update + Insert).
반환 값: UpdateResult 객체.matched_count:filter와 일치한 문서 수.modified_count: 실제로 수정된 문서 수 (값이 변경된 경우).upserted_id:upsert=True이고 새 문서가 삽입된 경우, 그_id.acknowledged: (boolean)
# "유관순" 사용자의 age를 19로, status 필드를 "martyr"로 업데이트
# 만약 "유관순" 사용자가 없으면 새로 생성 (upsert)
update_yoo_result = users_collection.update_one(
{"name": "유관순"},
{"$set": {"age": 19, "status": "martyr"}, "$currentDate": {"lastModified": True}},
upsert=True
)
print(f"일치: {update_yoo_result.matched_count}, 수정: {update_yoo_result.modified_count}, 업서트ID: {update_yoo_result.upserted_id}")update_many(filter, update, upsert=False, ...) 🔗
filter 조건에 맞는 모든
문서를 update 내용으로 수정합니다.
반환 값 및 옵션은 update_one과 유사합니다. # 모든 "독립운동가"의 "country" 필드를 "대한민국"으로 설정
update_country_result = users_collection.update_many(
{"occupation": " 독립운동가"},
{"$set": {"country": "대한민국"}}
)
print(f"독립운동가 국가 정보 업데이트: {update_country_result.modified_count}명 수정됨.")replace_one(filter, replacement, upsert=False, ...) 🔗
filter 조건에 맞는 첫 번째 문서를 replacement 문서로 완전히 교체
합니다. (_id는 변경 불가)
업데이트 연산자($set 등)를 사용하지 않습니다.4. 데이터 삭제 (Delete) 심화 🔗
delete_one(filter, ...) 🔗
filter조건에 맞는 첫 번째 문서를 삭제합니다.- 반환 값:
DeleteResult객체.deleted_count: 삭제된 문서 수.acknowledged: (boolean)
# age가 50 이상인 사용자 중 한 명 삭제 (조건에 맞는 첫 번째)
delete_one_result = users_collection.delete_one({"age": {"$gte": 50}})
print(f"50세 이상 사용자 중 1명 삭제: {delete_one_result.deleted_count}명 삭제됨.")delete_many(filter, ...) 🔗
filter조건에 맞는모든문서를 삭제합니다. (매우 주의해서 사용!)- 반환 값은
delete_one과 유사합니다.
# email 필드가 없는 모든 사용자 삭제
# delete_many_result = users_collection.delete_many({"email": {"$exists": False}})
# print(f"이메일 없는 사용자 삭제: {delete_many_result.deleted_count}명 삭제됨.") # 주석 처리 (실행 시 주의)Python에서 BSON 데이터 타입 다루기 🔗
MongoDB는 JSON과 유사한 BSON 형식을 사용하며, JSON보다 다양한 데이터 타입을 지원합니다.
PyMongo는 이러한 BSON 타입들을 Python의 네이티브 타입 또는 자체 제공 클래스와 매핑합니다.
ObjectId
: MongoDB 문서의 고유 ID.- Python에서는
bson.objectid.ObjectId클래스로 표현됩니다. - 새 ObjectId 생성:
ObjectId() - 문자열로부터 ObjectId 생성:
ObjectId("some_hex_string") - 자동 생성: 문서를 삽입할 때
_id필드를 지정하지 않으면 PyMongo가 자동으로 ObjectId를 생성하여 할당합니다.
Datetime
: 날짜와 시간.- Python의
datetime.datetime객체와 매핑됩니다.주의: 시간대(timezone) 정보가 없는 naive datetime 객체는 MongoDB에 UTC 기준으로 저장될 수 있습니다. 혼란을 피하려면 항상 시간대 정보가 있는 aware datetime 객체(예:datetime.datetime.now(datetime.timezone.utc))를 사용하는 것이 좋습니다.
Integer / Long
: PyMongo는 Python의 int 타입을 MongoDB의 32비트 또는 64비트 정수(상황에 따라)로 적절히 변환합니다.
Double
: Python의 float 타입과 매핑됩니다.
String
: Python의 str 타입.
Boolean
: Python의 bool 타입.
Array
: Python의 list 타입.
Embedded Document
: Python의 dict 타입.
Null
: Python의 None 타입.
Binary Data
: bson.binary.Binary 클래스.
Regular Expression
: bson.regex.Regex 클래스 또는 Python의 re 모듈로 컴파일된 정규표현식 객체.from bson.objectid import ObjectId
import datetime
# ObjectId 직접 사용 예시
my_specific_id = ObjectId()
doc_with_id = {"_id": my_specific_id, "data": "test"}
# users_collection.insert_one(doc_with_id)
# Datetime 사용 예시
event_doc = {
"event_name": "세미나 시작",
"start_time": datetime.datetime(2024, 5, 10, 9, 0, 0, tzinfo=datetime.timezone.utc),
"end_time": datetime.datetime(2024, 5, 10, 17, 0, 0, tzinfo=datetime.timezone(datetime.timedelta(hours=9))) # KST 예시
}
# users_collection.insert_one(event_doc)
# 조회 시 Python 객체로 자동 변환됨
retrieved_doc = users_collection.find_one({"_id": my_specific_id})
if retrieved_doc:
print(type(retrieved_doc['_id'])) # <class 'bson.objectid.ObjectId'>
# print(type(retrieved_doc['start_time'])) # <class 'datetime.datetime'>결론 🔗
전체 코드 보기
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure, BulkWriteError
from bson.objectid import ObjectId
import datetime
# --- MongoDB Atlas 연결 정보 ---
# 중요: 실제 사용 시에는 <username>, <password>, <cluster-url>, <dbname>을
# 본인의 Atlas 클러스터 정보로 반드시 수정해야 합니다.
# 보안을 위해 환경 변수나 설정 파일을 사용하는 것이 좋습니다.
ATLAS_URI = "mongodb+srv://<username>:<password>@<cluster-url>/<dbname>?retryWrites=true&w=majority"
DATABASE_NAME = "<dbname>" # Atlas 연결 문자열의 dbname과 동일하게, 또는 사용할 DB 이름
COLLECTION_NAME = "users_python_외전" # 테스트용 컬렉션 이름
def main():
client = None # finally 블록에서 사용하기 위해 외부에 선언
try:
# --- 1. MongoDB Atlas 연결 ---
print("MongoDB Atlas에 연결을 시도합니다...")
client = MongoClient(ATLAS_URI, serverSelectionTimeoutMS=5000) # 5초 타임아웃 설정
client.admin.command('ping') # 연결 상태 확인
print("MongoDB Atlas에 성공적으로 연결되었습니다!\n")
db = client[DATABASE_NAME]
users_collection = db[COLLECTION_NAME]
# 테스트를 위해 시작 시 컬렉션 내용 비우기 (선택 사항)
print(f"'{COLLECTION_NAME}' 컬렉션의 기존 문서를 삭제합니다...")
users_collection.delete_many({})
print("기존 문서 삭제 완료.\n")
# --- 2. 데이터 생성 (Create) 심화 ---
print("--- 데이터 생성 (Create) ---")
# 2.1 insert_one
new_user_doc_1 = {
"name": "유관순",
"age": 18,
"email": "yoo@example.com",
"tags": ["patriot", "activist"],
"joined_date": datetime.datetime(2024, 1, 1, 10, 0, 0, tzinfo=datetime.timezone.utc)
}
result_one = users_collection.insert_one(new_user_doc_1)
print(f"insert_one 성공, ID: {result_one.inserted_id}, 확인됨: {result_one.acknowledged}")
# 2.2 insert_many
my_specific_id_for_kimkoo = ObjectId() # 김구 선생님 _id 미리 생성
new_users_list = [
{"name": "안중근", "age": 30, "occupation": " 독립운동가", "country": "조선"},
{"name": "윤봉길", "age": 24, "occupation": " 독립운동가", "_id": ObjectId(), "country": "조선"},
{"name": "김구", "age": 50, "email": "kimkoo@example.com", "_id": my_specific_id_for_kimkoo, "country": "대한민국 임시정부"}
]
try:
result_many = users_collection.insert_many(new_users_list, ordered=False)
print(f"insert_many 성공, ID들: {result_many.inserted_ids}\n")
except BulkWriteError as bwe:
print(f"insert_many 중 대량 쓰기 오류 발생: {bwe.details}\n")
# --- 3. 데이터 조회 (Read) 심화 ---
print("--- 데이터 조회 (Read) ---")
# 3.1 find_one (특정 조건 + 정렬 + 프로젝션)
oldest_patriot = users_collection.find_one(
{"occupation": " 독립운동가"},
sort=[("age", -1)], # pymongo.DESCENDING 대신 -1 사용 가능
projection={"name": 1, "age": 1, "_id": 0}
)
if oldest_patriot:
print(f"find_one (가장 나이가 많은 독립운동가): {oldest_patriot}")
# 3.2 find (특정 조건 + 프로젝션 + 정렬 + limit)
korean_patriots = users_collection.find(
{"country": {"$in": ["조선", "대한민국 임시정부"]}}, # 조선 또는 대한민국 임시정부
projection={"name": 1, "age": 1, "country": 1, "_id": 0},
limit=5,
sort=[("name", 1)] # pymongo.ASCENDING 대신 1 사용 가능
)
print("find (조선/대한민국 임시정부 소속 독립운동가 최대 5명, 이름순):")
for patriot in korean_patriots:
print(patriot)
print("")
# --- 4. 데이터 수정 (Update) 심화 ---
print("--- 데이터 수정 (Update) ---")
# 4.1 update_one (upsert 예시)
update_yoo_result = users_collection.update_one(
{"name": "유관순"},
{"$set": {"age": 19, "status": "martyr"}, "$currentDate": {"lastModified": True}},
upsert=True
)
print(f"update_one ('유관순'): 일치: {update_yoo_result.matched_count}, 수정: {update_yoo_result.modified_count}, 업서트ID: {update_yoo_result.upserted_id}")
# 4.2 update_many
update_country_result = users_collection.update_many(
{"occupation": " 독립운동가"},
{"$set": {"country": "대한민국 독립유공자"}, "$inc": {"recognition_level": 1}}
)
print(f"update_many ('독립운동가' 국가 및 등급 수정): {update_country_result.modified_count}명 수정됨.\n")
# 수정된 김구 선생님 정보 확인
kimkoo_updated = users_collection.find_one({"_id": my_specific_id_for_kimkoo})
print(f"업데이트된 김구 선생님 정보: {kimkoo_updated}\n")
# --- 5. 데이터 삭제 (Delete) 심화 ---
print("--- 데이터 삭제 (Delete) ---")
# 5.1 delete_one
# 가장 어린 독립운동가 한 명 삭제 (테스트용)
youngest_fighter = users_collection.find_one({"occupation": "대한민국 독립유공자"}, sort=[("age", 1)])
if youngest_fighter:
delete_one_result = users_collection.delete_one({"_id": youngest_fighter["_id"]})
print(f"delete_one (가장 어린 독립유공자 '{youngest_fighter['name']}' 삭제): {delete_one_result.deleted_count}명 삭제됨.")
else:
print("삭제할 가장 어린 독립유공자가 없습니다.")
# 5.2 delete_many (특정 조건 - 주의해서 사용)
# 예시: 'status' 필드가 없는 문서 모두 삭제 (여기서는 실행하지 않음)
# delete_many_result = users_collection.delete_many({"status": {"$exists": False}})
# print(f"delete_many (status 필드 없는 문서 삭제): {delete_many_result.deleted_count}명 삭제됨.")
print("delete_many 예시는 주석 처리됨 (데이터 보호를 위해).\n")
# --- 6. BSON 데이터 타입 확인 예시 ---
print("--- BSON 데이터 타입 확인 ---")
doc_to_check = users_collection.find_one({"name": "유관순"})
if doc_to_check:
print(f"'유관순' 문서의 _id 타입: {type(doc_to_check['_id'])}")
print(f"'유관순' 문서의 joined_date 타입: {type(doc_to_check['joined_date'])}")
print(f"'유관순' 문서의 lastModified 타입: {type(doc_to_check.get('lastModified'))}") # 없을 수 있으므로 .get() 사용
print("")
except ConnectionFailure as e:
print(f"Atlas 연결 실패: {e}")
except BulkWriteError as bwe: # insert_many 등에서 발생 가능
print(f"대량 쓰기 작업 중 오류 발생: {bwe.details}")
except Exception as e:
print(f"알 수 없는 오류가 발생했습니다: {e}")
# 스택 트레이스 확인을 위해 다음 줄 주석 해제 가능
# import traceback
# traceback.print_exc()
finally:
if client:
client.close()
print("MongoDB 연결이 해제되었습니다.")
if __name__ == "__main__":
main()MongoDB Atlas에 연결을 시도합니다...
MongoDB Atlas에 성공적으로 연결되었습니다!
'users_python_외전' 컬렉션의 기존 문서를 삭제합니다...
기존 문서 삭제 완료.
--- 데이터 생성 (Create) ---
insert_one 성공, ID: 681c42b23ae26e5f6876b7c2, 확인됨: True
insert_many 성공, ID들: [ObjectId('681c42b23ae26e5f6876b7c5'), ObjectId('681c42b23ae26e5f6876b7c4'), ObjectId('681c42b23ae26e5f6876b7c3')]
--- 데이터 조회 (Read) ---
find_one (가장 나이가 많은 독립운동가): {'name': '안중근', 'age': 30}
find (조선/대한민국 임시정부 소속 독립운동가 최대 5명, 이름순):
{'name': '김구', 'age': 50, 'country': '대한민국 임시정부'}
{'name': '안중근', 'age': 30, 'country': '조선'}
{'name': '윤봉길', 'age': 24, 'country': '조선'}
--- 데이터 수정 (Update) ---
update_one ('유관순'): 일치: 1, 수정: 1, 업서트ID: None
update_many ('독립운동가' 국가 및 등급 수정): 2명 수정됨.
업데이트된 김구 선생님 정보: {'_id': ObjectId('681c42b23ae26e5f6876b7c3'), 'name': '김구', 'age': 50, 'email': 'kimkoo@example.com', 'country': '대한민국 임시정부'}
--- 데이터 삭제 (Delete) ---
삭제할 가장 어린 독립유공자가 없습니다.
delete_many 예시는 주석 처리됨 (데이터 보호를 위해).
--- BSON 데이터 타입 확인 ---
'유관순' 문서의 _id 타입: <class 'bson.objectid.ObjectId'>
'유관순' 문서의 joined_date 타입: <class 'datetime.datetime'>
'유관순' 문서의 lastModified 타입: <class 'datetime.datetime'>
MongoDB 연결이 해제되었습니다.오늘은 Python의 PyMongo 드라이버를 사용하여 MongoDB Atlas와 연동하는 기본적인 방법과 CRUD 작업을 심도 있게 살펴보았습니다.
PyMongo 설치부터 Atlas 연결 시 고려할 사항, 각 CRUD 메서드의 다양한 옵션과 반환 값, 그리고 BSON 데이터 타입을 Python에서 어떻게 다루는지까지 알아보았습니다.
다음편에서는 PyMongo를 활용한 고급 쿼리 기법, Python 코드를 통한 인덱스 관리 방법, 그리고 강력한 데이터 분석 도구인 집계 프레임워크(Aggregation Framework)를 Python에서 시작하는 방법에 대해 자세히 알아보겠습니다.
참고 🔗
- PyMongo 공식 튜토리얼: https://pymongo.readthedocs.io/en/stable/tutorial.html↗
- PyMongo API 문서 (
MongoClient): https://pymongo.readthedocs.io/en/stable/api/pymongo/mongo_client.html↗ - PyMongo API 문서 (컬렉션 레벨 작업): https://pymongo.readthedocs.io/en/stable/api/pymongo/collection.html↗
- BSON 타입과 Python 타입 매핑 (PyMongo 문서): https://pymongo.readthedocs.io/en/stable/bson.html↗