 벡터 데이터베이스와 RAG 시스템 연동 - n8n 파이프라인 5편Vector DB and RAG System Integration - n8n Pipeline Part 5
벡터 데이터베이스와 RAG 시스템 연동 - n8n 파이프라인 5편Vector DB and RAG System Integration - n8n Pipeline Part 5
📅
들어가기 전에 🔗
안녕하세요.
오늘은 LLM이 사실과 다른 내용을 지어내는 환각 현상을 방지하기 위해 RAG 파이프라인을 구축하는 과정을 다룹니다.
일반적인 인공지능은 학습하지 않은 사내 기밀 문서나 최신 규제 정보를 알지 못합니다.
이러한 한계를 극복하기 위해 외부 데이터를 검색하여 답변의 근거로 제공하는 기술을 검색 증강 생성 즉 RAG라고 부릅니다.
이번 포스팅에서는 AI 기술 동향 봇이 참고할 전문 가이드라인을 데이터베이스에 영구 저장하는 하나하나 차근차근 진행해 보겠습니다.
1단계 기반 데이터 작성하기 🔗
RAG 시스템의 뼈대가 될 기초 데이터를 먼저 준비해야 합니다.
n8n 워크플로우에
Code
노드를 추가하여 마크다운 형태의 텍스트 데이터를 생성합니다.Code 노드 텍스트 작성 실습 🔗
워크플로우 좌측의 노드 추가 버튼을 누르고
Code
노드를 검색하여 배치합니다.
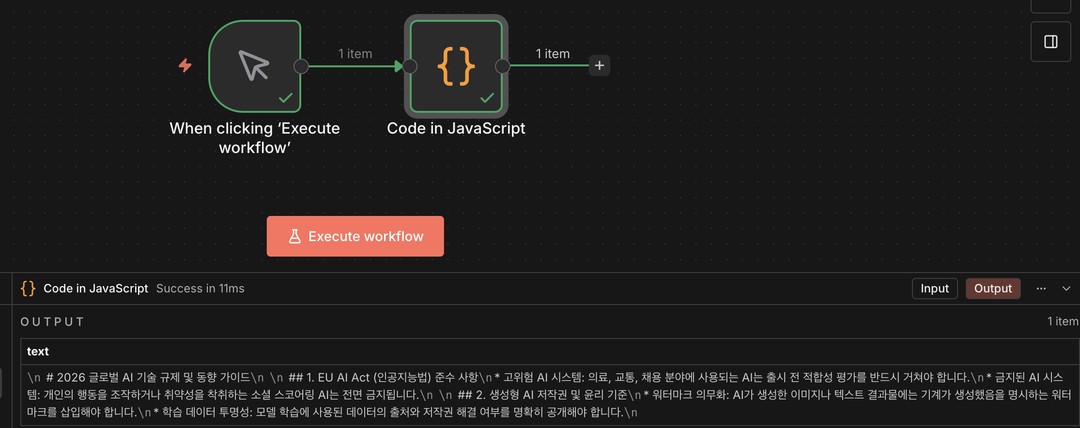
노드 설정 창을 열고 언어를 자바스크립트로 유지한 뒤 아래의 코드를 그대로 복사하여 붙여넣습니다.// LLM이 참고할 최신 AI 기술 규제 및 동향 가이드라인입니다.
return {
json: {
text: `
# 2026 글로벌 AI 기술 규제 및 동향 가이드
## 1. EU AI Act (인공지능법) 준수 사항
* 고위험 AI 시스템: 의료, 교통, 채용 분야에 사용되는 AI는 출시 전 적합성 평가를 반드시 거쳐야 합니다.
* 금지된 AI 시스템: 개인의 행동을 조작하거나 취약성을 착취하는 소셜 스코어링 AI는 전면 금지됩니다.
## 2. 생성형 AI 저작권 및 윤리 기준
* 워터마크 의무화: AI가 생성한 이미지나 텍스트 결과물에는 기계가 생성했음을 명시하는 워터마크를 삽입해야 합니다.
* 학습 데이터 투명성: 모델 학습에 사용된 데이터의 출처와 저작권 해결 여부를 명확히 공개해야 합니다.
`
}
};코드를 입력한 후 우측 하단의 실행 버튼을 누르면 JSON 객체 안에 텍스트 데이터가 정상적으로 담겨 출력되는 것을 확인할 수 있습니다.
Code 노드 실행 결과
2단계 텍스트 로더와 임베딩 설정 🔗
컴퓨터 시스템은 사람이 쓰는 문장을 있는 그대로 검색하거나 이해하지 못합니다.
문장의 의미와 문맥을 파악하기 위해 텍스트를 숫자의 배열로 바꾸어 주어야 하는데 이를 임베딩이라고 부릅니다.
먼저 텍스트를 시스템이 읽을 수 있는 문서 구조로 변환하는 도구를 꺼내어 둡니다.
화면에
Default Data Loader
노드를 검색하여 배치합니다.
이 노드는 선으로 연결하지 않고 잠시 화면 하단에 그대로 둡니다.
Default Data Loader 노드 배치
문서를 숫자로 바꾸어 줄 임베딩 인공지능 모델을 화면에 추가할 차례입니다.
Embeddings Google Gemini
노드를 검색하여 텍스트 로더 좌측에 배치합니다.
설정 창을 열고 인증 항목에서 Google Gemini API 키를 새로 등록합니다.모델 이름 항목이 models/gemini-embedding-001로 선택되어 있는지 확인합니다.
이 모델은 입력된 텍스트를 3072개의 차원을 가진 숫자 배열로 변환하는 역할을 수행합니다.
3단계 Pinecone 클라우드 DB 세팅 🔗
변환된 다차원 숫자 데이터를 보관하려면 기존의 관계형 데이터베이스가 아닌 벡터 전용 데이터베이스가 필요합니다.
우리는 무료로 사용할 수 있는 대표적인 벡터 데이터베이스인 Pinecone을 활용합니다.
Pinecone 공식 웹사이트에 접속하여 회원가입 후 로그인을 진행합니다.
좌측 메뉴에서 인덱스 생성 버튼을 누르고 이름 칸에 ai-trend-guide라고 입력합니다.
가장 중요한 부분은 차원수 설정입니다.
앞서 n8n에서 설정한 Gemini 임베딩 모델의 규격에 맞추기 위해 Dimensions 입력 칸에 숫자 3072를 정확히 적어주어야 합니다. (이 수치는 모델마다 다르므로 꼭 모델 설명을 참고하여 일치시켜야 합니다.)
생성 버튼을 누르면 데이터를 저장할 클라우드 공간이 마련되며 설정 메뉴에서 API 키를 발급받아 복사해 둡니다.
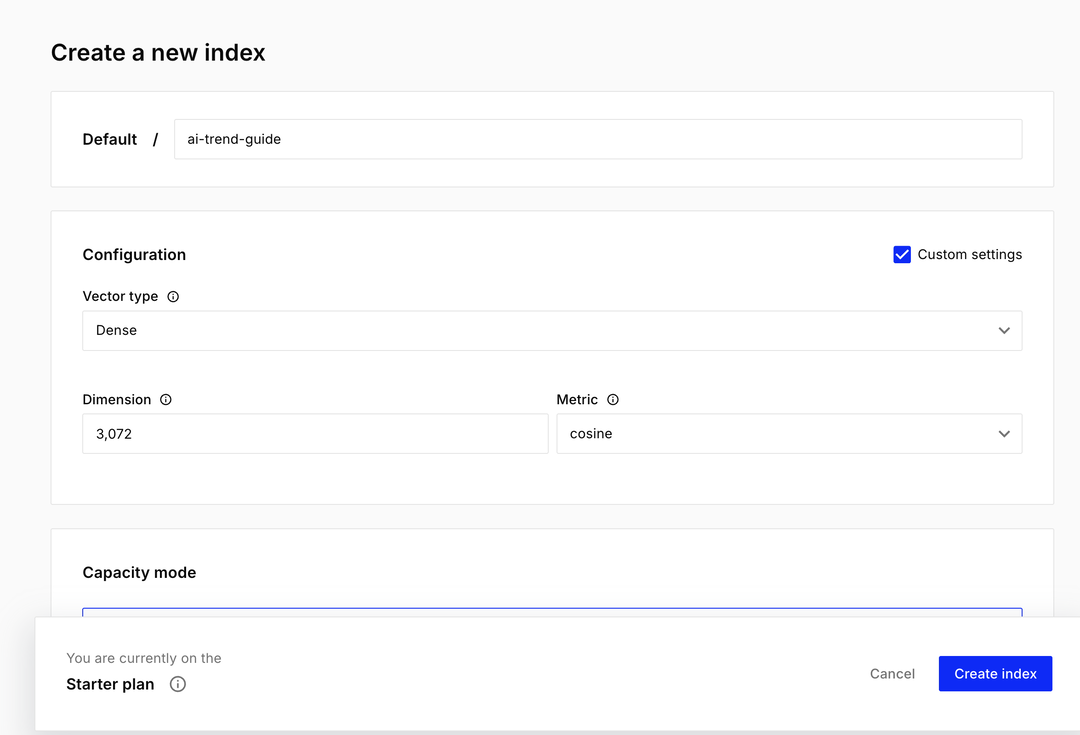
Pinecone 인덱스 생성
4단계 특수 노드 조립 및 최종 저장 🔗
n8n의 AI 관련 노드들은 일직선으로 연결하는 것이 아니라 중심이 되는 노드에 보조 부품들을 끼워 넣는 방식으로 조립해야 합니다.
이 연결 방식을 주의하여 데이터를 Pinecone 서버로 전송해 보겠습니다.
검색창에서
Pinecone
노드를 찾아 화면 우측에 배치합니다.
노드의 설정 창 상단에서 인증 항목을 열고 방금 복사해 온 Pinecone API 키를 등록해 줍니다.
작업 방식 속성을 데이터를 집어넣는다는 의미의 Insert 문서로 설정하고 인덱스 이름 항목에 ai-trend-guide를 적어줍니다.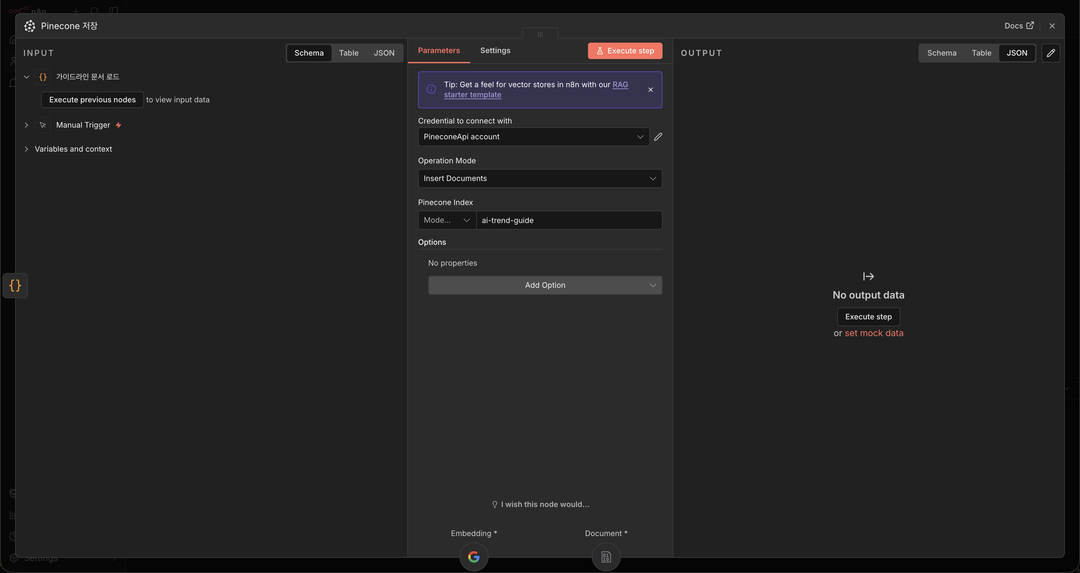
Pinecone 노드 설정
이제 흩어져 있는 노드들을
Pinecone
노드를 중심으로 결합합니다.
가이드라인 문서를 담고 있는 Code
노드의 우측 출력 선을 끌어와 Pinecone
노드의 좌측 Main 입력 단자에 연결합니다.
이어서 Default Data Loader
노드의 출력 선을 Pinecone
노드 하단의 Document 특수 입력 단자에 연결합니다.
마지막으로 Embeddings Google Gemini
노드의 출력 선을 Pinecone
노드 하단의 Embedding 특수 입력 단자에 연결합니다.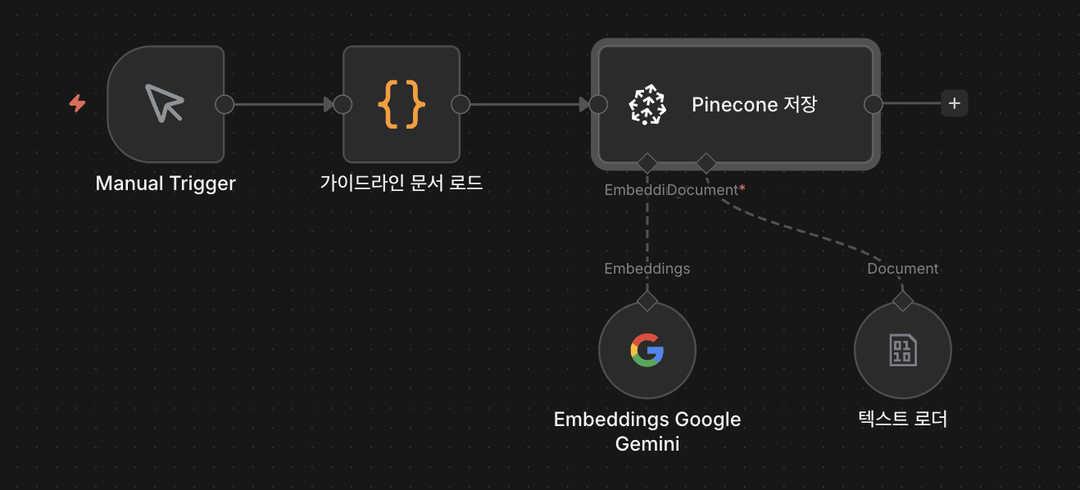
노드 결합
모든 조립이 끝났습니다.
가장 앞에 있는
Manual Trigger
노드의 실행 버튼을 누르면 텍스트 데이터가 변환되어 클라우드 데이터베이스에 성공적으로 저장됩니다.5단계 최종 워크플로우 결괏값 확인 🔗
앞서 설명한 모든 과정을 마친 최종 워크플로우의 형태를 JSON 코드로 공유합니다.
설정이 헷갈리거나 오류가 발생한다면 아래의 코드를 복사하여 n8n 화면에 그대로 붙여넣기 하시면 모든 노드 연결과 지정된 위치가 그대로 복원됩니다.
n8n 워크플로우 JSON 복사하기
{
"nodes":[
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position":[200, 300],
"id": "manual-trigger-id",
"name": "Manual Trigger"
},
{
"parameters": {
"jsCode": "return {\n json: {\n text: `\n# 2026 글로벌 AI 기술 규제 및 동향 가이드\n\n## 1. EU AI Act (인공지능법) 준수 사항\n* 고위험 AI 시스템: 의료, 교통, 채용 분야에 사용되는 AI는 출시 전 적합성 평가를 반드시 거쳐야 합니다.\n* 금지된 AI 시스템: 개인의 행동을 조작하거나 취약성을 착취하는 소셜 스코어링 AI는 전면 금지됩니다.\n\n## 2. 생성형 AI 저작권 및 윤리 기준\n* 워터마크 의무화: AI가 생성한 이미지나 텍스트 결과물에는 기계가 생성했음을 명시하는 워터마크를 삽입해야 합니다.\n* 학습 데이터 투명성: 모델 학습에 사용된 데이터의 출처와 저작권 해결 여부를 명확히 공개해야 합니다.\n `\n }\n};"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position":[400, 300],
"id": "code-node-id",
"name": "가이드라인 문서 로드"
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.documentDefaultDataLoader",
"typeVersion": 1.1,
"position":[800, 500],
"id": "data-loader-id",
"name": "텍스트 로더"
},
{
"parameters": {
"modelName": "models/gemini-embedding-001"
},
"type": "@n8n/n8n-nodes-langchain.embeddingsGoogleGemini",
"typeVersion": 1,
"position":[600, 500],
"id": "embedding-node-id",
"name": "Embeddings Google Gemini"
},
{
"parameters": {
"mode": "insert",
"pineconeIndex": "ai-trend-guide",
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.vectorStorePinecone",
"typeVersion": 1,
"position":[600, 300],
"id": "pinecone-node-id",
"name": "Pinecone 저장"
}
],
"connections": {
"Manual Trigger": {
"main": [[
{
"node": "가이드라인 문서 로드",
"type": "main",
"index": 0
}
]
]
},
"가이드라인 문서 로드": {
"main": [[
{
"node": "Pinecone 저장",
"type": "main",
"index": 0
}
]
]
},
"텍스트 로더": {
"ai_document": [[
{
"node": "Pinecone 저장",
"type": "ai_document",
"index": 0
}
]
]
},
"Embeddings Google Gemini": {
"ai_embedding": [[
{
"node": "Pinecone 저장",
"type": "ai_embedding",
"index": 0
}
]
]
}
}
}이 과정은 최초 1회만 실행해 두면 데이터가 영구적으로 보존됩니다.
다음 6편에서는 이 데이터베이스를 실시간 검색 도구로 활용하며 최신 기사를 수집하고 요약하는 다중 에이전트 브리핑 봇을 구현해 보겠습니다.
결론 🔗
이번 포스팅에서는 전문 지식을 시스템에 부여하기 위한 RAG 파이프라인의 데이터 적재 과정을 실습했습니다.
Pinecone 클라우드 환경 세팅부터 모델의 차원수를 맞추고 n8n 특유의 AI 노드 결선 방식을 통해 벡터 데이터베이스의 작동 원리를 구체적으로 파악할 수 있었습니다.