 다중 에이전트 뉴스 브리핑 봇 구현 - n8n 파이프라인 6편Multi Agent News Briefing Bot System Implementation - n8n Pipeline Part 6
다중 에이전트 뉴스 브리핑 봇 구현 - n8n 파이프라인 6편Multi Agent News Briefing Bot System Implementation - n8n Pipeline Part 6
📅
들어가기 전에 🔗
안녕하세요.
오늘은 최신 AI 기술 동향을 주제로 뉴스를 수집하고 분석하는 브리핑 봇 구축 과정을 다룹니다.
하나의 거대한 LLM 모델에 모든 작업을 맡기면 처리 속도가 느려지고 결과물의 품질이 떨어집니다.
이를 해결하기 위해 역할을 나누어 처리하는 Multi-Agent 아키텍처를 도입합니다.
이번 실습에서는 크롤링 차단이나 RSS 주소 변경으로 인한 오류를 방지하기 위해 정해진 예시 데이터를 활용합니다.
두 개의 인공지능이 언어 모델과 협력하여 뉴스를 선별하고 브리핑을 작성하는 전체 파이프라인을 구성합니다.
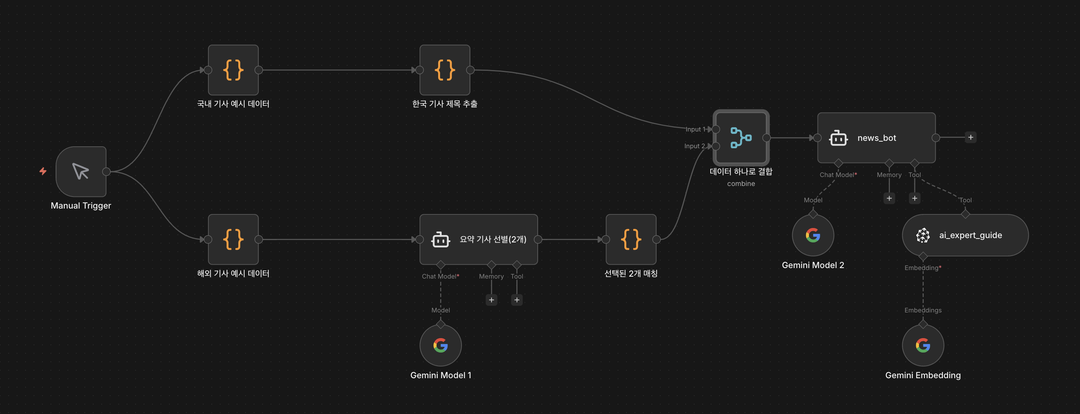
전체 파이프라인
1단계 수동 트리거와 예시 데이터 생성 🔗
실제 인터넷에서 기사를 수집하는 대신
Code
노드를 사용하여 국내와 해외의 기사 데이터를 흉내 내는 예시 데이터를 만듭니다.
파이프라인의 시작점인 Manual Trigger
노드를 배치하고 그 뒤에 두 개의 Code
노드를 나란히 배치합니다.// 국내 기사 예시 데이터
return[
{ json: { title: "국내 AI 스타트업 투자 유치", link: "url1" } },
{ json: { title: "한국형 LLM 모델 성능 평가 발표", link: "url2" } }
];// 해외 기사 예시 데이터
const rawData =[
{ title: "OpenAI 새로운 모델 발표", link: "url3", contentSnippet: "새로운 추론 모델이 공개되었습니다" },
{ title: "EU 인공지능 법안 발효", link: "url4", contentSnippet: "유럽의 AI 규제가 본격적으로 시작됩니다" },
{ title: "자율주행 기술의 한계", link: "url5", contentSnippet: "센서 오작동으로 인한 사고가 발생했습니다" }
];
let globalData = "[글로벌 AI 기사 목록]\n";
rawData.forEach((a, i) => {
globalData += `${i}. ${a.title} (${a.link})\n 요약: ${a.contentSnippet}\n\n`;
});
return { json: { globalData: globalData, rawData: rawData } };Manual Trigger
노드의 우측 출력 단자에서 선을 두 갈래로 나누어 뽑아냅니다.
하나는 국내 기사용 Code
노드에 연결하고 다른 하나는 해외 기사용 Code
노드에 동시에 연결합니다.
이렇게 구성하면 실행 버튼을 한 번 눌렀을 때 두 개의 데이터가 동시에 생성됩니다.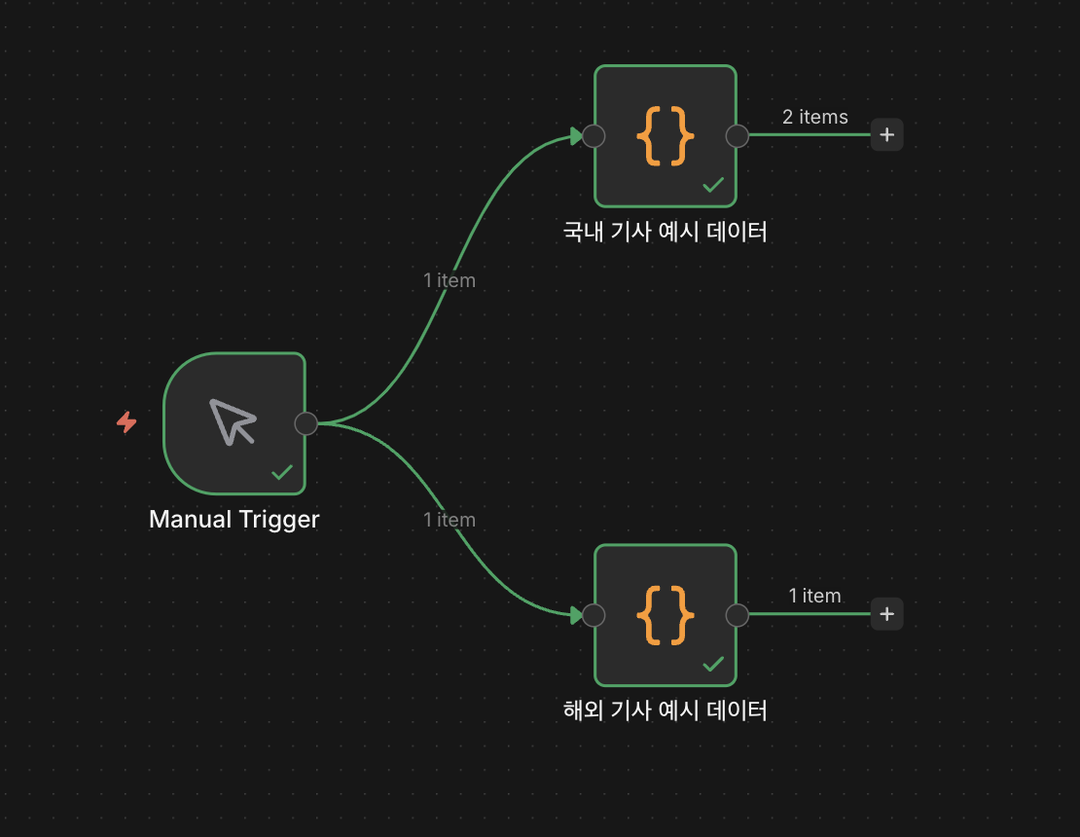
Manual Trigger과 예시 데이터 연결
자바스크립트 기반 데이터 압축 🔗
수백 개의 기사 원문을 그대로 LLM에 전달하면 입력 한도 초과 오류가 발생하거나 API 비용이 증가합니다.
이를 방지하기 위해 국내 기사를 담당하는 노드 뒤에 새로운
Code
노드를 연결합니다.
본문을 지우고 제목만 추출하여 하나의 긴 문자열로 결합하는 로직을 작성합니다.
이 노드는 국내 기사 데이터에 연결해주도록 하겠습니다.const allItems = $input.all().map(item => item.json);
let titleList = "";
// 한국 기사들의 본문을 제외하고 제목만 추출하여 결합합니다
allItems.forEach((article) => {
titleList += `- ${article.title || "제목 없음"}\n`;
});
// 압축된 데이터를 단일 JSON 객체로 반환하여 LLM 입력 부담을 줄입니다
return { json: { koreanTitles: titleList } };실전 위한 추천 RSS 피드 리스트 🔗
예시 데이터를 이용한 실습이 끝난 후 시스템을 실제 자동화 환경으로 전환할 때 사용할 수 있는 검증된 RSS 피드 목록을 소개합니다.
예시 데이터를 생성했던
Code
노드를 삭제하고 그 자리에 RSS Read
노드를 연결하여 아래의 주소들을 입력하면 됩니다.
추후에 각 매체들에서 제공하는 데이터들을 살펴보고, Code 노드를 사용해 적당히 조절해보도록 합시다.글로벌 메인스트림 테크 매체 🔗
언어 모델이 한국어로 번역하고 요약하기 좋은 해외 테크 매체들입니다.
- TechCrunch (스타트업, 실리콘밸리 동향, 신기술 투자 소식)
https://techcrunch.com/feed/ - The Verge (소비자 관점의 IT 기기, 빅테크 기업 정책, AI 트렌드)
https://www.theverge.com/rss/index.xml - Wired (기술이 사회와 경제에 미치는 영향 등 심층 분석 기사)
https://www.wired.com/feed/rss
개발자 및 딥테크 특화 커뮤니티 🔗
소프트웨어 엔지니어링과 아키텍처 트렌드를 파악하기 좋은 소스입니다.
- Hacker News (개발자들과 Y Combinator 출신들이 모여 실시간으로 기술 토론을 나누는 커뮤니티)
https://news.ycombinator.com/rss - MIT Technology Review (양자컴퓨팅, 최첨단 AI 등 미래 지향적 딥테크 논문과 연구 동향)
https://www.technologyreview.com/feed/
국내 IT 산업 동향 매체 🔗
국내 빅테크 기업과 IT 정책 동향을 폭넓게 파악할 수 있는 매체들입니다.
- 전자신문 (국내 IT 산업, 반도체, 하드웨어 전반 동향)
https://rss.etnews.com/Section901.xml - 구글 뉴스 대한민국 과학 기술 카테고리 (국내 여러 언론사의 IT 뉴스 종합)
https://news.google.com/rss/topics/CAAqJggKIiBDQkFTRWdvSUwyMHZNRGRqTVhZU0FtdHZHZ0pMVWlnQVAB?hl=ko&gl=KR&ceid=KR:ko
2단계 1차 Agent 기사 선별 🔗
다시 실습으로 돌아와 추출된 여러 해외 기사 중 파급력이 큰 2개를 선별하기 위해 첫 번째
Agent
노드를 사용합니다.
n8n에서 Agent
노드를 작동시키려면 반드시 언어 모델을 연결해 주어야 합니다.Gemini Chat Model
노드를 화면에 추가하고 1차 Agent
노드의 Language Model 입력 단자에 선으로 연결합니다.
이 단계의 인공지능은 텍스트를 길게 서술할 필요가 없으므로 정확한 배열 인덱스만 추출하도록 시스템 프롬프트를 통제합니다.프롬프트에 출력 예시를 배열 형태로 지정하면 인공지능은 조건에 맞는 숫자 배열만 반환합니다.
이후
Code
노드를 하나 더 연결하여 인공지능이 반환한 숫자 배열을 실제 원본 기사 데이터와 매칭합니다.당신은 글로벌 뉴스 편집장입니다. 아래 기사 제목과 요약을 읽고 파급력이 큰 기사 딱 2개를 고르세요
[조건]
반드시 기사 앞에 붙은 '인덱스 번호'만 골라서 JSON 배열 형태로 출력하세요
[출력 예시]
[0, 1]
[후보 목록]
{{ $json.globalData }}
Gemini 모델이 연결된 1차 Agent 노드
이 이후에 노드에서는 인공지능이 반환한 배열을 파싱하여 실제 기사 제목과 요약이 포함된 텍스트로 변환하는 로직을 작성합니다.
이렇게 하면 1차 Agent가 해외 기사 중에서 핵심적인 2개를 선별하여 다음 단계로 넘겨줄 수 있습니다.
const text = $input.first().json.output || "";
const rawData = $('해외 기사 예시 데이터').first().json.rawData;
let indexes =[0, 1];
try {
const match = text.match(/\[\s*\d+\s*,\s*\d+\s*\]/);
if (match) indexes = JSON.parse(match[0]).slice(0, 2);
} catch(e) {}
let selectedGlobal = "[핵심 기사 2개]\n\n";
indexes.forEach((idx) => {
const article = rawData[idx];
if(article) selectedGlobal += `제목: ${article.title}\n링크: ${article.link}\n내용: ${article.contentSnippet}\n\n`;
});
return { json: { selectedGlobal } };3단계 2차 Agent 통합 브리핑 및 필수 도구 연동 🔗
메인 작가 역할을 수행할 두 번째 인공지능을 구성할 차례입니다.
최적화된 한국 기사의 제목 리스트와 1차 인공지능이 엄선한 해외 핵심 기사의 본문을
Merge
노드로 결합합니다.도구 설명과 임베딩 모델 연결 🔗
결합된 데이터를 2차
Agent
노드에 전달합니다.
이 노드 역시 구동을 위해 새로운 Gemini Chat Model
노드를 추가하여 Language Model 입력 단자에 연결합니다.이어서 외부 지식창고를 검색하기 위해
Vector Store Pinecone
노드를 화면에 꺼내어 2차 Agent
노드의 Tool 입력 단자에 연결합니다.
이때 주의할 점은 벡터 데이터베이스 노드가 텍스트를 검색하려면 문장을 숫자로 변환해 줄 보조 부품이 반드시 필요하다는 점입니다.
Embeddings Google Gemini
노드를 새롭게 추가하여 Pinecone
노드 하단의 Embedding 특수 입력 단자에 연결해야 에러가 발생하지 않습니다.마지막으로
Pinecone
설정 창의 Tool Description 항목에 AI 규제나 가이드라인 지식이 필요할 때 검색하라는 문구를 입력합니다.너는 최신 AI 전문 뉴스 브리핑 봇이야.
제공된 한국 기사 제목과 해외 핵심 기사 2개를 바탕으로 통합 브리핑을 작성해.[작성 규칙]
1. 한국 기사 제목의 동향을 분석해 오늘의 AI 트렌드를 요약할 것.
2. 해외 핵심 기사 2개를 요약하고 인사이트를 덧붙일 것.
3. 기사 요약 시 필요하다면 제공된 RAG 도구를 검색하여 AI 규제에 대한 전문 시각을 반영할 것.해당 노드를 실행하면 인공지능이 스스로 필요성을 판단하여 외부 지식창고를 참조한 뒤 뉴스 브리핑 텍스트를 생성합니다.
4단계 최종 워크플로우 스크립트 확인 🔗
앞서 설명한 예시 데이터 생성부터 언어 모델 및 임베딩 도구가 올바르게 결선된 Multi-Agent 워크플로우를 JSON 코드로 공유합니다.
아래의 코드를 복사하여 n8n 화면에 붙여넣기 하시면 전체 노드 연결이 즉시 복원됩니다.
예시 데이터 기반 Multi-Agent 파이프라인 JSON
{
"nodes":[
{
"parameters": {},
"type": "n8n-nodes-base.manualTrigger",
"typeVersion": 1,
"position":[160, 460],
"id": "manual-trigger",
"name": "Manual Trigger"
},
{
"parameters": {
"jsCode": "return[\n { json: { title: \"국내 AI 스타트업 투자 유치\", link: \"url1\" } },\n { json: { title: \"한국형 LLM 모델 성능 평가 발표\", link: \"url2\" } }\n];"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position":[450, 280],
"id": "mock-korea",
"name": "국내 기사 예시 데이터"
},
{
"parameters": {
"jsCode": "const rawData =[\n { title: \"OpenAI 새로운 모델 발표\", link: \"url3\", contentSnippet: \"새로운 추론 모델이 공개되었습니다\" },\n { title: \"EU 인공지능 법안 발효\", link: \"url4\", contentSnippet: \"유럽의 AI 규제가 본격적으로 시작됩니다\" },\n { title: \"자율주행 기술의 한계\", link: \"url5\", contentSnippet: \"센서 오작동으로 인한 사고가 발생했습니다\" }\n];\nlet globalData = \"[글로벌 AI 기사 목록]\\n\";\nrawData.forEach((a, i) => {\n globalData += `${i}. ${a.title} (${a.link})\\n 요약: ${a.contentSnippet}\\n\\n`;\n});\nreturn { json: { globalData: globalData, rawData: rawData } };"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position":[450, 600],
"id": "mock-global",
"name": "해외 기사 예시 데이터"
},
{
"parameters": {
"jsCode": "const allItems = $input.all().map(item => item.json);\nlet titleList = \"\";\nallItems.forEach((article) => {\n titleList += `- ${article.title || \"제목 없음\"}\\n`;\n});\nreturn { json: { koreanTitles: titleList } };"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [850, 280],
"id": "code-korea-extract",
"name": "한국 기사 제목 추출"
},
{
"parameters": {
"promptType": "define",
"text": "=당신은 글로벌 뉴스 편집장입니다. 아래 기사 제목과 요약을 읽고 파급력이 큰 기사 딱 2개를 고르세요\n[조건]\n반드시 기사 앞에 붙은 '인덱스 번호'만 골라서 JSON 배열 형태로 출력하세요\n[출력 예시]\n[0, 1]\n[후보 목록]\n{{ $json.globalData }}"
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 3.1,
"position":[850, 600],
"id": "agent-selector",
"name": "요약 기사 선별(2개)"
},
{
"parameters": {
"jsCode": "const text = $input.first().json.output || \"\";\nconst rawData = $('해외 기사 예시 데이터').first().json.rawData;\nlet indexes =[0, 1];\ntry {\n const match = text.match(/\\[\\s*\\d+\\s*,\\s*\\d+\\s*\\]/);\n if (match) indexes = JSON.parse(match[0]).slice(0, 2);\n} catch(e) {}\nlet selectedGlobal = \"[핵심 기사 2개]\\n\\n\";\nindexes.forEach((idx) => {\n const article = rawData[idx];\n if(article) selectedGlobal += `제목: ${article.title}\\n링크: ${article.link}\\n내용: ${article.contentSnippet}\\n\\n`;\n});\nreturn { json: { selectedGlobal } };"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position":[1200, 600],
"id": "code-matcher",
"name": "선택된 2개 매칭"
},
{
"parameters": {
"mode": "combine",
"combineBy": "combineByPosition"
},
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2,
"position": [1400, 400],
"id": "merge-final",
"name": "데이터 하나로 결합"
},
{
"parameters": {
"promptType": "define",
"text": "=너는 최신 AI 기술 전문 뉴스 브리핑 봇이야\n제공된 한국 기사 제목과 핵심 기사 2개를 바탕으로 통합 브리핑을 작성해\n\n[한국 기사 제목]\n{{ $json.koreanTitles }}\n\n[핵심 기사 2개]\n{{ $json.selectedGlobal }}"
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 3.1,
"position":[1600, 400],
"id": "agent-main",
"name": "news_bot"
},
{
"parameters": {
"mode": "retrieve-as-tool",
"toolDescription": "AI 규제, EU 인공지능법, 저작권, 기술 윤리 등에 대한 전문 지식이 필요할 때 이 도구를 검색하세요",
"pineconeIndex": { "value": "ai-trend-guide" }
},
"type": "@n8n/n8n-nodes-langchain.vectorStorePinecone",
"typeVersion": 1.3,
"position":[1750, 600],
"id": "tool-rag",
"name": "ai_expert_guide"
},
{
"parameters": {
"modelName": "models/gemini-2.5-flash-lite"
},
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"typeVersion": 1,
"position":[850, 800],
"id": "llm-gemini-1",
"name": "Gemini Model 1"
},
{
"parameters": {
"modelName": "models/gemini-2.5-flash-lite"
},
"type": "@n8n/n8n-nodes-langchain.lmChatGoogleGemini",
"typeVersion": 1,
"position":[1550, 600],
"id": "llm-gemini-2",
"name": "Gemini Model 2"
},
{
"parameters": {
"modelName": "models/gemini-embedding-001"
},
"type": "@n8n/n8n-nodes-langchain.embeddingsGoogleGemini",
"typeVersion": 1,
"position":[1750, 800],
"id": "embedding-rag",
"name": "Gemini Embedding"
}
],
"connections": {
"Manual Trigger": {
"main":[[
{ "node": "국내 기사 예시 데이터", "type": "main", "index": 0 },
{ "node": "해외 기사 예시 데이터", "type": "main", "index": 0 }
]
]
},
"국내 기사 예시 데이터": {
"main": [[ {"node": "한국 기사 제목 추출", "type": "main", "index": 0} ] ]
},
"해외 기사 예시 데이터": {
"main": [[ {"node": "요약 기사 선별(2개)", "type": "main", "index": 0} ] ]
},
"한국 기사 제목 추출": {
"main": [[ {"node": "데이터 하나로 결합", "type": "main", "index": 0} ] ]
},
"요약 기사 선별(2개)": {
"main": [[ {"node": "선택된 2개 매칭", "type": "main", "index": 0} ] ]
},
"선택된 2개 매칭": {
"main": [[ {"node": "데이터 하나로 결합", "type": "main", "index": 1} ] ]
},
"데이터 하나로 결합": {
"main": [[ {"node": "news_bot", "type": "main", "index": 0} ] ]
},
"Gemini Model 1": {
"ai_languageModel": [[ {"node": "요약 기사 선별(2개)", "type": "ai_languageModel", "index": 0} ] ]
},
"Gemini Model 2": {
"ai_languageModel": [[ {"node": "news_bot", "type": "ai_languageModel", "index": 0} ] ]
},
"ai_expert_guide": {
"ai_tool": [[ {"node": "news_bot", "type": "ai_tool", "index": 0} ] ]
},
"Gemini Embedding": {
"ai_embedding": [[ {"node": "ai_expert_guide", "type": "ai_embedding", "index": 0} ] ]
}
}
}이 코드를 활용하면 외부 API 차단 걱정 없이 데이터 처리와 인공지능 협업 로직을 안전하게 테스트할 수 있습니다.
결론 🔗
이번 포스팅에서는 크롤링 오류를 배제한 예시 데이터를 바탕으로 Multi-Agent 아키텍처를 구현했습니다.
이후 시스템을 확장할 때 오늘 공유해 드린 추천 RSS 리스트를 활용하면 실무 수준의 강력한 뉴스 브리핑 자동화 시스템을 완성할 수 있습니다.
이렇게 진행하다보니 문제가 하나 있었습니다. 바로 디스코드에서 글자 수 제한이 걸려서 긴 뉴스 브리핑을 전송할 수 없다는 점입니다.
다음 7편에서는 메신저의 글자 수 제한을 초과할 경우 파일로 변환하여 전송하는 예외 처리 라우팅 기법을 다루겠습니다.