 ETA 거리 의도 피처 엔지니어링 전략 - XGBoost 추천시스템 3편ETA Feature Engineering Strategy - XGBoost Recommendation System Part 3
ETA 거리 의도 피처 엔지니어링 전략 - XGBoost 추천시스템 3편ETA Feature Engineering Strategy - XGBoost Recommendation System Part 3
📅
들어가기 전에 🔗
안녕하세요.
1편에서는 추천 문제를 랭킹으로 정의하고 라벨을 설계했습니다.
2편에서는 Station Place Edge 데이터셋을 만들고 정제 파이프라인을 구성했습니다.
이번 3편에서는 ETA 이동시간을 공정성 피처로 바꾸는 방법을 다룹니다.
실습 코드와 데이터셋은 GitHub 저장소↗에서 확인하실 수 있습니다.
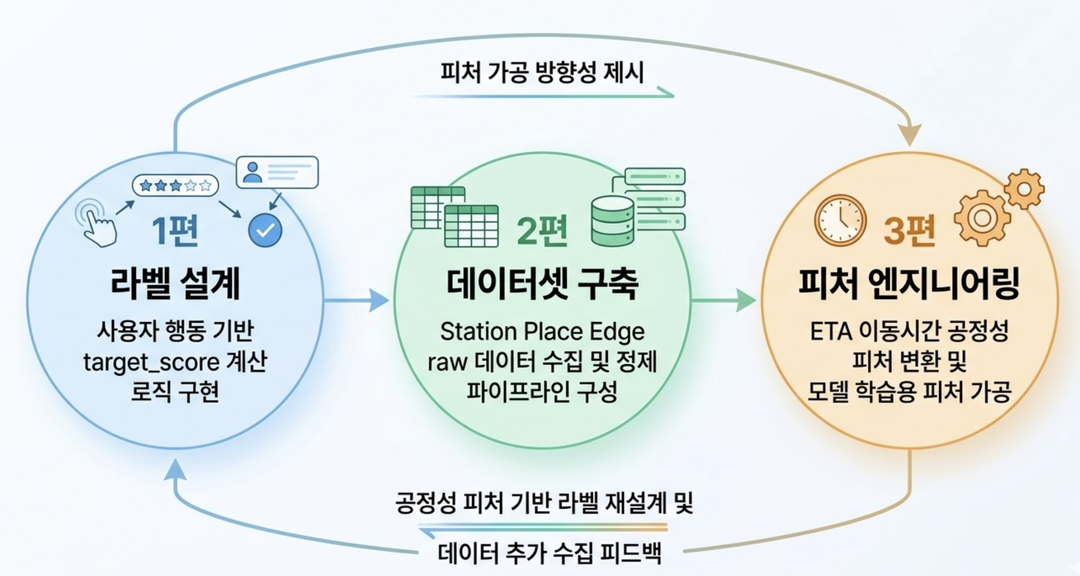
시리즈 흐름
이번 편 로드맵 🔗
- 피처와 라벨의 차이를 먼저 정리합니다.
- ETA 공정성 피처와 의도 피처 설계 기준을 설명합니다.
scripts와ml코드가 실제로 무엇을 하는지 단계별로 해설합니다.NDCG결과를 읽는 기준과 단순화 체크리스트를 정리합니다.
피처란 무엇인가 🔗
머신러닝에서 피처는 모델이 판단에 사용하는 입력 정보입니다.
학습 데이터 한 줄은 보통 방과 후보 장소 조합으로 구성됩니다.
각 피처는 그 조합의 성질을 숫자나 범주로 표현합니다.
예를 들어
eta_mean은 평균 이동시간이고 eta_range는 참여자 간 이동시간 격차입니다.
purpose_match는 모임 목적과 장소 카테고리 일치 여부를 나타냅니다.라벨과 피처의 차이 🔗
- 라벨은 모델이 맞혀야 할 정답입니다.
- 피처는 라벨을 예측하기 위한 단서입니다.
이번 실습에서는 행동 로그를 기반으로 만든
target_score를 라벨로 사용합니다.
그리고 ETA 통계량과 의도 정보를 피처로 사용합니다.왜 ETA를 공정성 피처로 쓰는가 🔗
약속 장소 추천에서는 평균 이동시간만 보면 불공정이 가려질 수 있습니다.
예를 들어 세 명의 ETA가 15분 15분 45분이면 평균은 25분이라 좋아 보입니다.
하지만 한 명은 명확히 불리한 상태입니다.
그래서 ETA 분포 자체를 피처로 넣어야 체감 공정성을 모델이 학습할 수 있습니다.
이동비용 피처군 🔗
eta_mean: 참여자 평균 이동시간입니다.eta_std: 참여자 이동시간의 퍼짐 정도입니다.eta_range: 최소와 최대 ETA 차이입니다.eta_min: 최소 이동시간입니다.eta_max: 최대 이동시간입니다.eta_p90: 상위 지연 구간을 반영한 보수적 지표입니다.
의도 피처군 🔗
purpose_match:purpose와category의 의미 일치 여부입니다.hour_bucket: 시간대를 아침 오후 저녁 같은 버킷으로 묶은 값입니다.group_size: 참여자 수로, 편차 확대 가능성을 반영합니다.

공정성 피처가 필요한 이유
학습 코드 핵심 로직 🔗
먼저 파이썬 학습 코드의 핵심 수식을 확인합니다.
후보 점수 생성 로직 🔗
eta_range = float(np.max(etas) - np.min(etas))
eta_mean = float(np.mean(etas))
bonus = _purpose_category_bonus(purpose, str(place.get("category", "")))
score = 1.2 * eta_range + 0.3 * eta_mean - 8.0 * bonuseta_range와eta_mean으로 이동 부담과 형평성을 함께 반영합니다.- 목적 일치 보너스를 크게 두어 의도 적합성을 강화합니다.
라벨 합성 로직 🔗
click_score = weights.click if int(action.get("is_clicked", 0)) == 1 else 0.0
vote_score = weights.vote if int(action.get("is_voted", 0)) == 1 else 0.0
final_score = weights.final if int(action.get("is_final_selected", 0)) == 1 else 0.0
rating = float(action.get("rating", 0) or 0)
rating = max(0.0, min(5.0, rating))
feedback_score = (rating / 5.0) * weights.rating_max_bonus
return click_score + vote_score + final_score + feedback_score- 퍼널 행동을 하나의 연속값 라벨로 합성해 랭킹 학습에 사용합니다.
ETA 피처 생성 로직 🔗
etas_np = np.array(etas, dtype=float)
eta_mean = float(np.mean(etas_np))
eta_std = float(np.std(etas_np))
eta_max = float(np.max(etas_np))
eta_min = float(np.min(etas_np))
eta_range = float(eta_max - eta_min)
eta_p90 = float(np.percentile(etas_np, 90))- 평균만이 아니라 분포 통계를 함께 넣어 공정성 정보를 보존합니다.
NDCG 계산 로직 🔗
def ndcg_at_k(y_true, y_score, group_ids, k):
ndcgs = []
for gid in np.unique(group_ids):
m = group_ids == gid
t = y_true[m]
s = y_score[m]
order = np.argsort(-s)
ideal = np.argsort(-t)
dcg = _dcg(t[order], k=k)
idcg = _dcg(t[ideal], k=k)
ndcgs.append(0.0 if idcg == 0.0 else dcg / idcg)
return float(np.mean(ndcgs)) if ndcgs else 0.0- 같은
room_id그룹 안에서 상위 순위 품질을 평가합니다.
아래 스크립트 섹션에서는 이 코드를 어떤 순서로 실행하는지 연결해 설명합니다.
실습 순서 정리 🔗
실습은 환경 준비 -> 데이터 생성 -> 피처 생성 -> 평가 순서로 진행합니다.
운영체제별 실행 파일 🔗
Mac & Linux는
_mac_linux.sh로 끝나는 스크립트, Windows는 _windows.ps1로 끝나는 스크립트를 사용합니다.실행 전 체크포인트 🔗
- 단계 순서를 바꾸지 않습니다.
- Mac에서 XGBoost import 오류가 발생하면
scripts/install_libomp_mac.sh를 먼저 실행합니다. - 결과는 절대값보다 피처셋 간 상대 비교 중심으로 해석합니다.
스크립트 내부 설명 🔗
1) 환경 준비 스크립트 🔗
#!/usr/bin/env bash
set -euo pipefail
python3 -m venv .venv-ml
source .venv-ml/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-ml.txt
echo "Environment ready."set -euo pipefail은 실패를 즉시 노출해 조용한 실패를 줄입니다.- 가상환경 분리로 시스템 파이썬과 의존성 충돌을 방지합니다.
2) 데이터 생성과 라벨링 스크립트 🔗
#!/usr/bin/env bash
set -euo pipefail
source .venv-ml/bin/activate
python ml/synthetic_generator_part3.py --stations ml/out/stations.csv --places ml/out/places.csv --n-rooms 80 --seed 42 --out-rooms ml/rooms_part3.jsonl --out-actions ml/synthetic_actions_part3.jsonl
python ml/label_builder.py --input ml/synthetic_actions_part3.jsonl --output ml/synthetic_actions_part3_labeled.jsonl- 같은
seed를 사용해 재현성을 확보합니다. - 생성된 행동 로그를
target_score라벨로 변환해 학습 가능한 형태로 만듭니다.
3) 피처 생성 스크립트 🔗
#!/usr/bin/env bash
set -euo pipefail
source .venv-ml/bin/activate
python ml/feature_builder_part3.py --stations ml/out/stations.csv --places ml/out/places.csv --edges ml/out/edges.csv --rooms ml/rooms_part3.jsonl --labeled-actions ml/synthetic_actions_part3_labeled.jsonl --out-dir ml/out_part3- ETA 분포 통계를 계산해
train_ltr.csv를 생성합니다. - 함께 생성되는
feature_report.json에는 분할 정보와 ETA 소스 사용량이 기록됩니다.
4) 평가 스크립트 🔗
#!/usr/bin/env bash
set -euo pipefail
source .venv-ml/bin/activate
python ml/evaluate_part3.py --data ml/out_part3/train_ltr.csv --feature-report ml/out_part3/feature_report.json --out ml/out_part3/eval_report.json --k 4no_eta,eta_mean_only,full_fairness를 동일 조건에서 비교합니다.- 결과 파일
eval_report.json이 해석의 기준이 됩니다.
출력 예시와 해석 🔗
{
"models": {
"no_eta": {
"ndcg_at_k": 0.553259
},
"eta_mean_only": {
"ndcg_at_k": 0.541776
},
"full_fairness": {
"ndcg_at_k": 0.669059
}
}
}해석 포인트 🔗
eta_mean_only는 평균만 반영하므로 불공정 신호를 충분히 반영하지 못합니다.full_fairness는 분포 피처를 함께 사용해 순위 품질이 개선됩니다.
결론 🔗
이번 3편에서는 ETA를 평균값 하나가 아닌 분포로 다루어 공정성을 피처에 반영했습니다.
또한 목적 시간대 그룹크기 같은 의도 피처를 결합해 추천 품질을 안정적으로 끌어올리는 방법을 확인했습니다.
다음 4편에서는 이 피처 테이블을 기반으로 XGBoost 학습 파이프라인과 실패 시 fallback 설계를 다루겠습니다.